Real world navigation requires robots to operate in unfamiliar, dynamic environments, sharing spaces with humans. Navigating around humans is especially difficult because it requires predicting their future motion, which can be quite challenging. We propose a novel framework for navigation around humans which combines learning-based perception with model-based optimal control. Specifically, we train a Convolutional Neural Network (CNN)-based perception module which maps the robot's visual inputs to a waypoint, or next desired state. This waypoint is then input into planning and control modules which convey the robot safely and efficiently to the goal. To train the CNN we contribute a photo-realistic bench-marking dataset for autonomous robot navigation in the presence of humans. The CNN is trained using supervised learning on images rendered from our photo-realistic dataset. The proposed framework learns to anticipate and react to peoples' motion based only on a monocular RGB image, without explicitly predicting the future human motion. Our method generalizes well to unseen buildings and humans in both simulation and real world environments. Furthermore, our experiments demonstrate that combining model-based control and learning leads to better and more data-efficient navigational behaviors as compared to a purely learning based approach.
HumANav enables zero-shot transfer of learning based navigation algorithms directly from simulation to reality. We hope that HumANav can be a useful tool for the broader visual navigation, computer vision, and robotics communities.
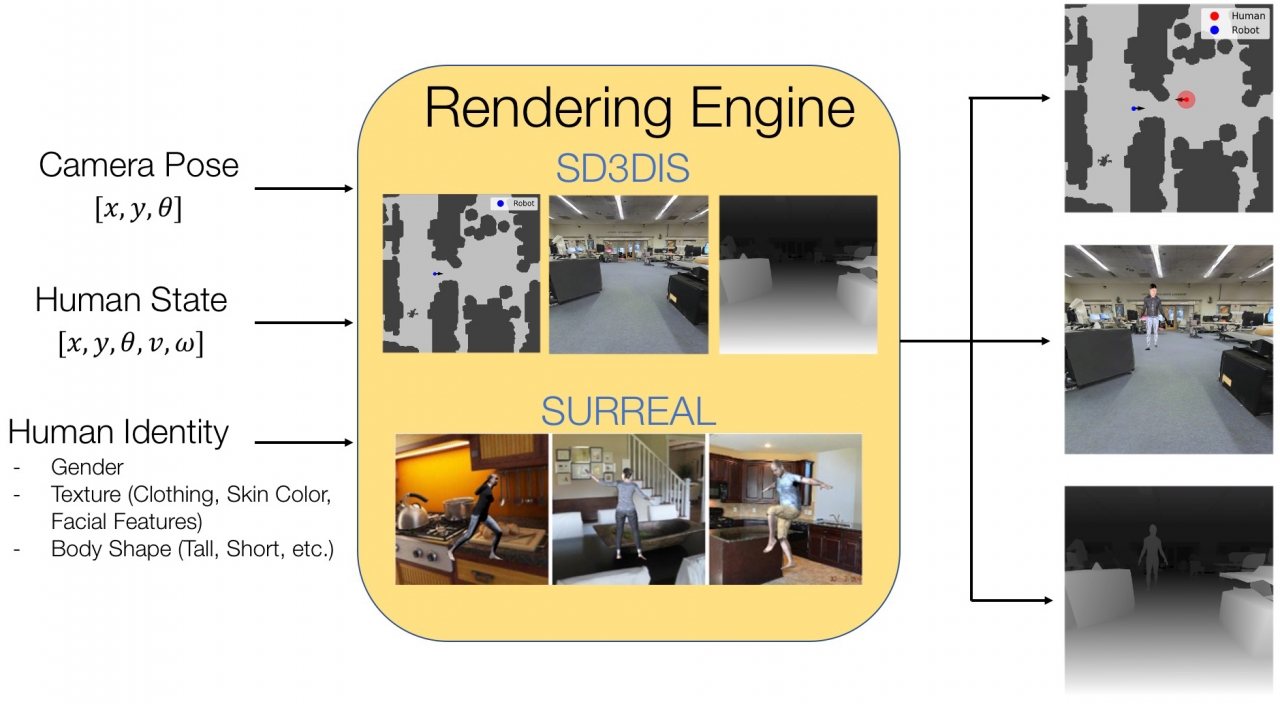
For rendering purposes, we use the Swiftshader rendering engine, a CPU based rendering engine for photorealistic visuals (rgb, disparity, surface normal, etc.) from textured meshes used in. We use mesh scans of office buildings from the Stanford Large Scale 3d Indoor Spaces Dataset (SD3DIS), however the rendering engine is independent of the meshes used. In principle, textured meshes from scans of any office buildings can be used. For human meshes we turn to the SURREAL Dataset which renders images of synthetic humans in a variety of poses, genders, body shapes, and lighting conditions. Though the meshes themselves are synthetic, the human poses in the SURREAL dataset come from real human motion capture data and contain a variety of actions including running, jumping, dancing, acrobatics, and walking. We focus on the subset of poses in which the human is walking.
DARPA Assured Autonomy program under agreement number FA8750-18-C-0101
NSF under the CPS Frontier project VeHICaL project (1545126)
NSF grants 1739816 and 1837132
UC-Philippine-California Advanced Research Institute under project IIID-2016-005
SRC under the CONIX Center
Berkeley Deep Drive
Google-BAIR Commons program
ORGANIZATION
University of California, Berkeley, California, USA